

Defining the Problem of Music Plagiarism Detection
"Music plagiarism detection" — it sounds straightforward, but when we actually started the research, the first wall was in an unexpected place. What exactly is this problem? Nobody had ever agreed on that.
A Problem Nobody Defined
We dug through existing research. There was a field called Cover Song Identification, another called Audio Fingerprinting, and somewhere in between sat Music Plagiarism Detection. The three looked similar but were fundamentally different.
Fingerprinting like Shazam is technology for matching "what song is this." It finds unique patterns in an audio signal, so it can identify different recordings of the same song. Cover song detection determines "is this song a cover of that song." It recognizes the original even when the arrangement is different.
Plagiarism is critically different from both. It's not the entire track but specific segments where problems can arise. The chorus melody of 4 bars might be similar, but comparing whole tracks would naturally conclude they're "different songs." And the instrumentation might differ, the mix might differ, the genre might differ, yet the topline melody alone is identical. An audio signal approach would never catch that.
No paper had clearly articulated these distinctions. Honestly, even our team's previous papers were vague on this point.
So We Defined It Ourselves
This time, we committed to getting the problem definition right from the start. We debated internally for quite a while. We broke down what plagiarism detection needs to solve into three stages.
First, finding suspect tracks from a massive database. Second, pinpointing exactly which segment matches which segment. Third, if possible, explaining why they're similar — is it the melody, the chord progression, or the rhythm?
It seems obvious in hindsight, but once we wrote it down explicitly, the research direction became much clearer.

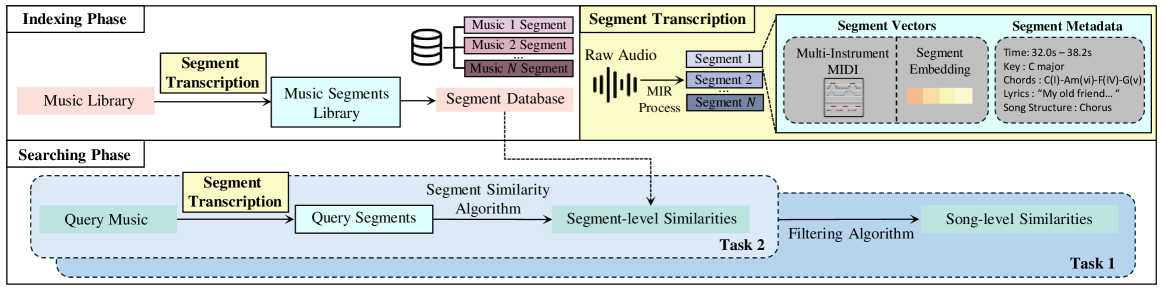
Seeing Through Segments
The approach is to split tracks into segments and ask "is this segment of Song A similar to that segment of Song B?"
We needed a process to convert audio into structured musical data. Comparing raw audio directly would be thrown off by instrumentation and mixing differences, so we opted to first extract musical elements — melody, chords, rhythm — and compare those.
This way, we could naturally explain "why this section is similar." Comparing melody transcriptions lets you say "the melodies are similar." Comparing chord progressions lets you say "the harmonic movement is similar."
Looking Back
The most valuable part of this research wasn't model performance — it was the problem definition itself. Just articulating "what exactly plagiarism detection needs to solve" made all subsequent research significantly smoother.
There were challenges too. Getting actual plagiarism dispute data was incredibly difficult. Public datasets are virtually nonexistent, so we had to create synthetic data ourselves. Validating with real legal dispute cases remains future work.
Still, we found our direction. Not simply judging music as "similar or different," but a system that can explain where and why it's similar. That's the path we're on.
Written by Sunghyun Ko (MIPPIA Research)