

Can We Tell If AI Made the Music? — Our Journey
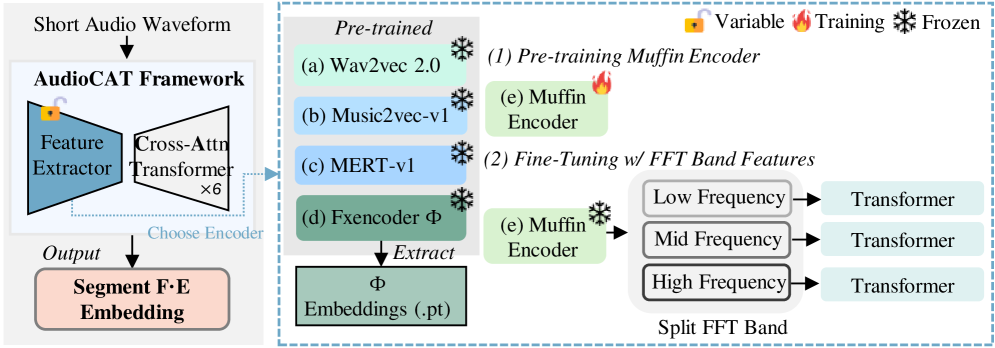
I pulled a track from Suno. A three-minute pop song. It was pretty decent. There was a chorus, a bridge, and the arrangement was surprisingly polished. Honestly — just by listening, I couldn't tell whether it was made by AI or a human.
That's where our story begins.
The First Question
What's different between human-made music and AI-generated music? Not many people have seriously thought about this. We didn't know where to start either.
"Maybe the timbre is different?" "Maybe the mixing quality is lower?" — We tried these intuitive guesses, but modern generative AI handles those surprisingly well. Surface-level differences weren't going to cut it.
Then a hypothesis came to mind. Structure. Human-made music has a flow that spans the entire track. The intro builds tension, the verse tells a story, the chorus explodes. Does AI really nail this macro-level flow?
The 4-Bar Unit
Music has a concept called bars. In pop music, 4 bars typically form one phrase. We decided to call this a "segment." When you slice a track into 4-bar chunks, you can see what role each piece plays in the overall composition.
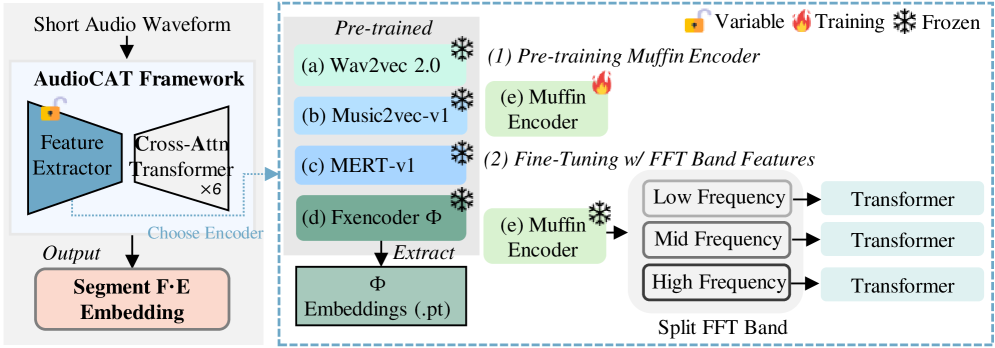
We wanted to test if this idea held up. We used beat tracking to find downbeats, split tracks into 4-bar segments, and extracted features from each segment for comparison.
The results were fascinating. In human-made music, the relationships between segments were clear. Part A and Part B contrasted well, and when the chorus repeated, there were subtle variations. AI music, on the other hand — each segment sounded fine on its own, but the relationships between segments were weaker.
Two Perspectives
A dilemma emerged. Sometimes you can tell it's AI from a single segment, and sometimes you need to look at the entire track's structure. We needed to capture both.
So we split the model into two stages. The first stage looks at each segment's "content" — timbre, melody, rhythm. The second stage lines up all segments and examines the overall "structure."
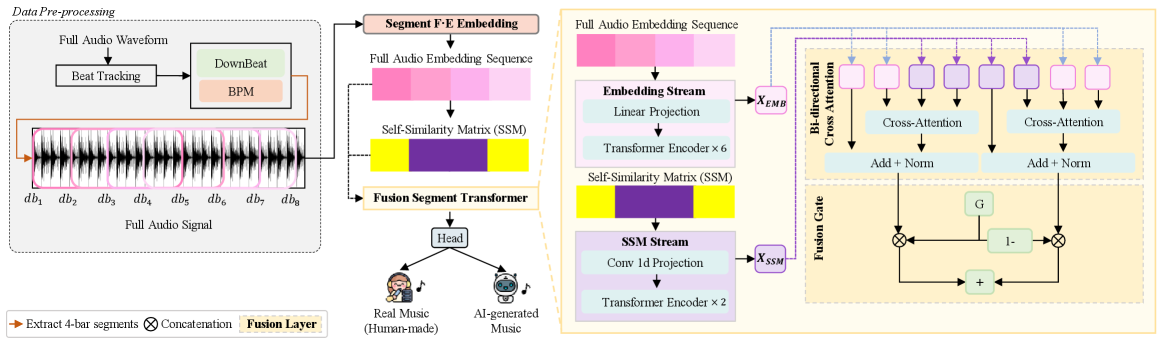
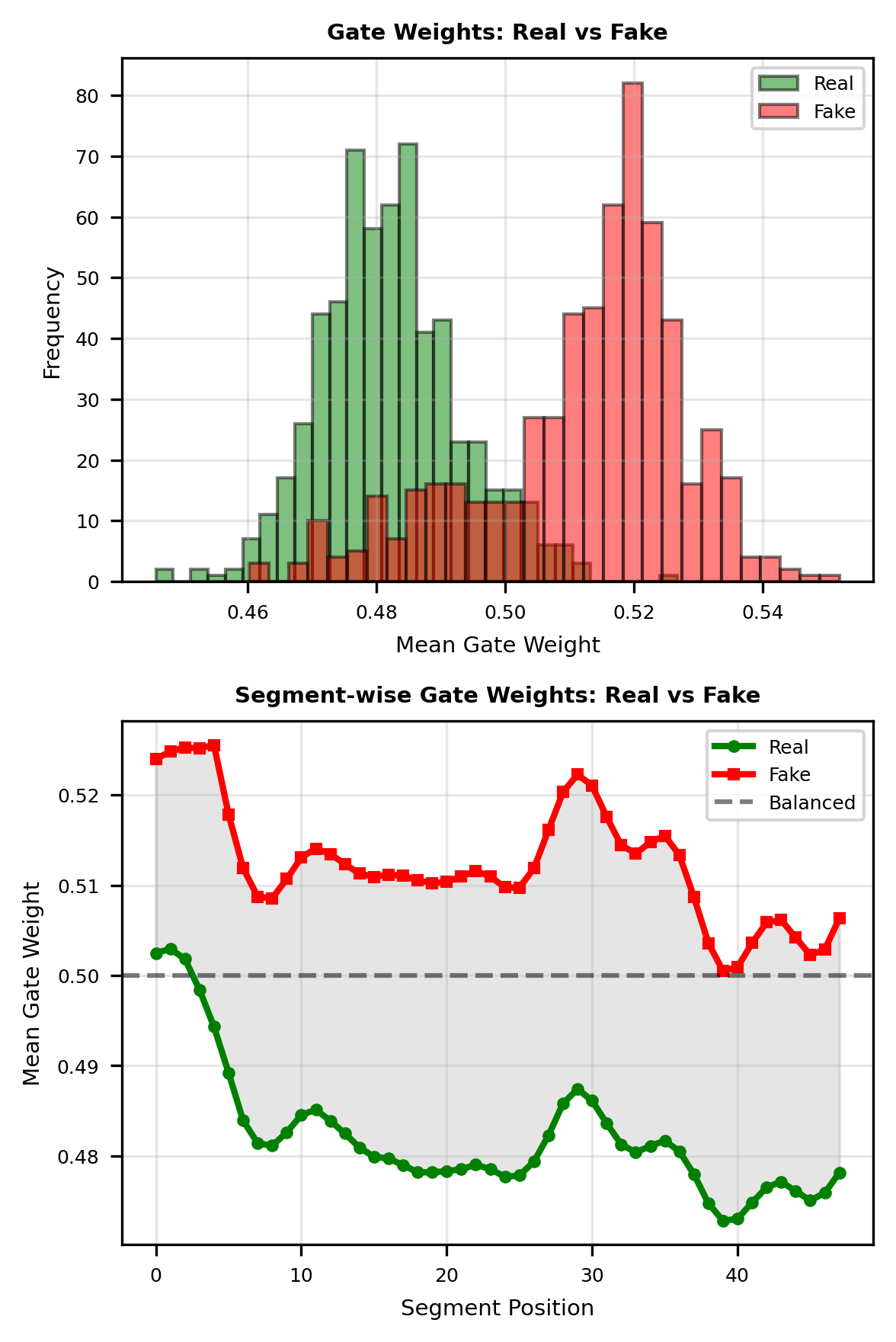
We discovered something interesting. When the model judged "this is human-made," it relied mainly on structural features. When it judged "this is AI," it leaned more on content features. The strength of human music lies in structure, and the weakness of AI music is also in structure.
What We Want to Explore Next
Working on this research actually gave us more things we want to try. AI music generation keeps evolving, and there's plenty of room for our model to grow alongside it.
Seeing music not just as an audio signal, but as a work with structure. This perspective could apply not only to AI detection but to the broader problem of understanding music. More genres, newer AI models, and real-time services — the direction for expansion is clear, and that's actually exciting.
Written by Yumin Kim (MIPPIA Research)