

음악 표절 탐지라는 문제를 정의하기까지
"음악 표절 탐지" — 말로는 단순해 보이는데, 막상 연구를 시작하려니 첫 번째 벽이 의외의 곳에 있었다. 이게 정확히 뭔 문제인 건지, 아무도 합의한 적이 없더라.
아무도 정의하지 않은 문제
기존 연구들을 쭉 훑어봤다. Cover Song Identification이라는 분야가 있고, Audio Fingerprinting이라는 분야가 있고, 그 사이 어딘가에 Music Plagiarism Detection이 있었다. 근데 세 개가 다 비슷해 보이면서도 다르다.
Shazam 같은 핑거프린팅은 "이 노래가 뭔지" 맞추는 기술이다. 음향 신호의 고유한 패턴을 찾는 거라, 같은 곡의 다른 녹음도 찾아낸다. 커버곡 탐지는 "이 곡이 저 곡의 커버인지" 판단한다. 편곡이 달라도 원곡을 알아보는 거다.
표절은 이 두 가지와 결정적으로 다르다. 곡 전체가 아니라 특정 구간에서만 문제가 생길 수 있다. 코러스 4마디 멜로디만 비슷한 건데, 곡 전체를 비교하면 당연히 "다른 곡"이라고 나온다. 그리고 악기도 다르고 믹싱도 다르고 장르도 다른데 탑라인 멜로디만 같은 경우도 있다. 음향 신호로 접근하면 절대 잡을 수 없다.
이런 차이를 명확하게 정리한 논문이 없었다. 솔직히 우리 팀의 이전 논문도 이 부분이 모호했다.
그래서 직접 정의했다
이번에는 문제 정의부터 제대로 하자고 마음먹었다. 팀 내부에서 꽤 오래 토론했다. 표절 탐지가 풀어야 하는 문제를 세 단계로 나눴다.
첫째, 대규모 데이터베이스에서 의심곡을 찾아내는 것. 둘째, 어느 구간이 어느 구간과 비슷한지 정확히 짚어내는 것. 셋째, 가능하다면 왜 비슷한지 — 멜로디인지, 코드인지, 리듬인지 — 설명하는 것.
지금 보면 당연해 보이지만, 이걸 명시적으로 적어놓고 나니까 연구 방향이 훨씬 선명해졌다.

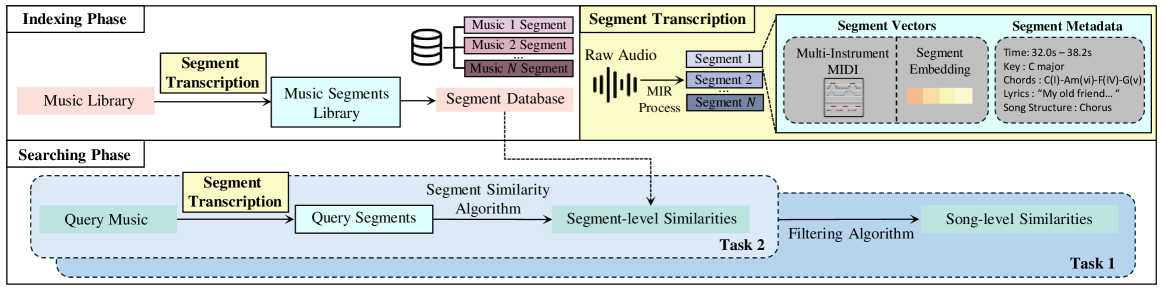
세그먼트로 쪼개서 보기
곡을 세그먼트 단위로 나눠서, "A곡의 이 세그먼트가 B곡의 저 세그먼트와 비슷한가"를 보는 방식이다.
음원을 구조화된 음악 데이터로 바꾸는 과정이 필요했다. 오디오에서 바로 비교하면 악기 편성이나 믹싱 차이에 휘둘리니까, 음악적인 요소 — 멜로디, 코드, 리듬 — 를 먼저 뽑아내고 그걸로 비교하는 방식을 택했다.
이렇게 하니까 "이 구간이 왜 비슷한지"도 자연스럽게 설명할 수 있게 됐다. 멜로디 트랜스크립션끼리 비교하면 "멜로디가 비슷하다"고 말할 수 있고, 코드 프로그레션끼리 비교하면 "코드 진행이 비슷하다"고 말할 수 있으니까.
돌아보며
이 연구에서 가장 가치 있었던 건 모델 성능이 아니라 문제 정의 그 자체였다고 생각한다. "표절 탐지가 정확히 뭘 풀어야 하는 문제인지" 정리한 것만으로도 후속 연구가 훨씬 수월해졌다.
아쉬운 점도 있다. 실제 표절 분쟁 데이터를 구하기가 너무 어려웠다. 공개된 데이터셋이 거의 없어서, 유사 데이터를 직접 만들어야 했다. 실제 법적 분쟁 사례로 검증하는 건 앞으로의 숙제다.
그래도 방향은 잡았다. 음악 표절을 단순히 "비슷하다/다르다"로 판단하는 게 아니라, 어디가 왜 비슷한지 설명할 수 있는 시스템. 이게 우리가 가고 있는 길이다.
글 · 고성현 (MIPPIA Research)